
🧠 AI: 딥시크에 'ㄷ'은 3개 들어있지.
[2025년 9월 9일 먀 AI 뉴스레터로 발행한 글입니다.]

Deepseek(중국산 LLM)에 알파벳 D가 총 몇 개 들어갈까요?
정답은 '하나'입니다.
챗GPT를 비롯한 챗봇형 LLM이 날이 갈수록 똑똑해지고 있습니다. 2023년에 이미 GPT-4는 미국 변호사 시험도 통과했다는 기사가 나왔는데요. 그렇다면 위와 같은 질문은 손쉽게 풀 수 있겠지요?
하지만 놀랍게도, 이름의 주인공인 딥시크는 열 번의 시도에서 모두 2개, 혹은 3개라고 답했습니다. 메타 AI와 앤트로픽의 클로드 3.7 소넷도 별반 차이가 없었습니다. 여러 번 질문하자, 7개라고 말한 기록도 있습니다. 알파벳을 구별할 줄 안다면 어린이도 풀 법한 문제를, 변호사 시험까지 통과한 LLM은 왜 틀릴까요? 또, 모르면 모른다고 말하면 안되는 걸까요? 🤨
모르는 문제는 일단 찍어볼게
혹시, 조삼모사 공부법에 대해 들어보셨나요?

고사성어 '조삼모사'에 대한 농담. 출처: 페이스북
조삼모사 공부법은 '조금 모르면 3번, 아예 모르면 4번 찍기'를 일컫는 우스갯소리입니다. 모른다고 빈칸으로 둘 바에야, 찍기라도 하면 맞을 확률이 올라가기 때문이지요. 언어 모델의 환각 문제는 바로 이 '조삼모사 공부법'에 이유가 있습니다. 정답이면 1점, 틀리거나 답을 안 쓰면 0점을 주는 시험에서는 모르는 문제가 나왔을 때 무조건 찍는 전략이 유리합니다. 아무 답도 안 하면 0점이지만, 찍으면 낮은 확률이나마 맞출 가능성이 있으니까요.🪓
현재 대부분의 벤치마크 평가는 모델이 맞힌 문항 비율만을 주요 지표로 삼습니다. 모델이 틀린 답을 얼마나 자신있게 말했는지, 모르겠다고 솔직히 답했는지 등은 반영되지 않지요. 오픈AI는 이번 연구에서 인기 있는 벤치마크 10여 개를 조사했는데요. 아래 결과를 살펴볼까요?
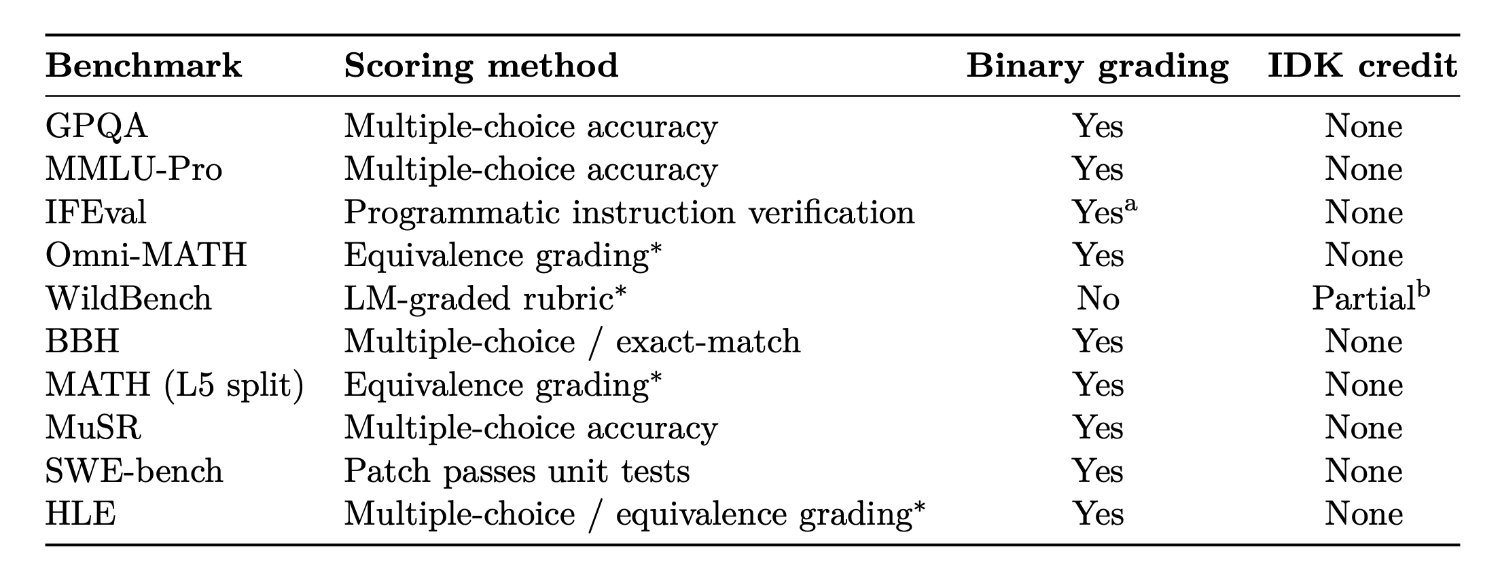
주요 언어 모델 평가의 채점 구조. 대부분의 벤치마크가 이진(Binary)법 위주로 모델을 평가하며, '모르겠다'라는 답변에 대한 어떠한 인정 점수(IDK credit)도 없다. 출처: 논문
분석된 10개 평가 중 9개는 무조건 정답만 점수로 인정하고 오답이나 무응답은 똑같이 0점을 줍니다. WildBench만이 일부 '모르겠다'는 응답에 부분 점수를 주는 구조인데, 이마저도 세부 기준을 살펴보면 실효성이 제한적입니다. 결과적으로 다른 평가들과 큰 차이가 없지요. 이러한 환경에서는 당연히 모델이 정답을 모르는 경우에도 최대한 그럴듯한 답을 생성하도록 학습됩니다. 틀린 답을 하든 모른다고 하든 점수상으로는 똑같다 보니, 모델 입장에서는 추측이라도 해 봐야 평균 정확도가 높아질 수 있지요.
그 결과, 벤치마크 평가에서 높은 정확도를 기록하는 언어 모델은 환각 답변 또한 남발하는 경향을 보입니다. 오픈AI 내부 평가에서 짧고 명확한 질문으로 구성된 벤치마크인 SimpleQA로 두 모델을 시험했는데요. 결과를 살펴볼까요?
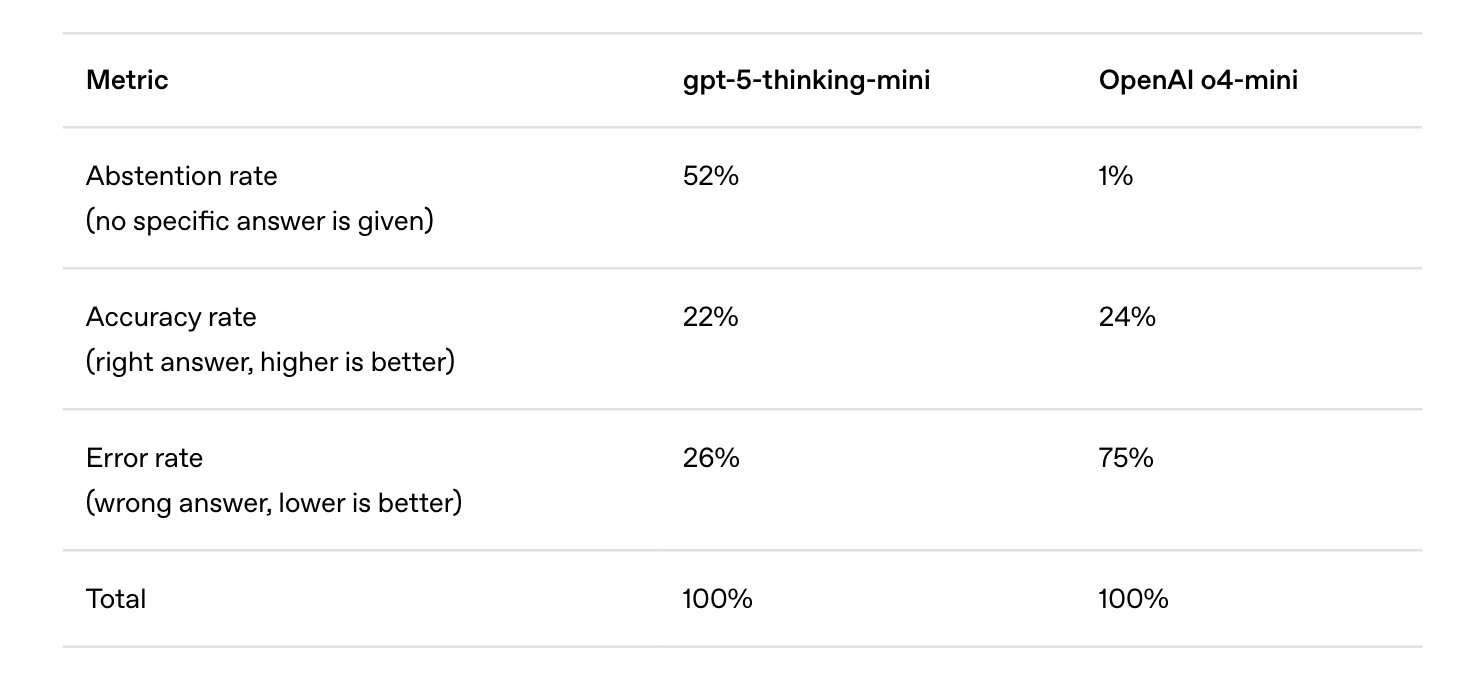
결과 비교. 출처: 오픈AI
최신 GPT-5에 기반한 미니 모델은 52%의 질문에 아예 답을 하지 않고 넘겼지만 정확도 22%에 환각률 26%를 보였습니다. 반면 이전 세대 모델인 o4 미니 모델은 답을 하지 않은 질문이 1% 밖에 되지 않았습니다. 거의 모든 질문에 답변했지요. 따라서 정확도가 24%로 약간 높았지만, 환각률이 무려 75%에 달했습니다. 하지만 많은 벤치마크가 이런 경우 정확도 수치로 모델 성능을 비교하기 때문에, 개발자들은 정확도 수치를 올리기 위해서라도 모델이 모르는 질문에도 끝까지 답을 하도록 유인하게 됩니다.
내 사전에 '모른다'는 없어
언어 모델이 환각 증세를 보이는 또 다른 근본 원인은 훈련 단계에 있습니다. 일부 오류가 불가피하게 심어지는 구조라고 연구진은 주장하는데요. 좀 더 알아보겠습니다.
최신 LLM은 방대한 텍스트 데이터를 읽으며 다음 단어를 예측하는 방식으로 일을 합니다. 이때 입력으로 들어가는 텍스트는 대부분 사람이 쓴 올바른 문장들인데요. LLM은 잘못된 정보를 걸러서 학습하지 않고, 오로지 텍스트의 통계적 패턴만을 학습합니다. 그렇다면 모델은 훈련 데이터에서 본 적 없는 새로운 사실 질문에 대해 어떤 태도를 보일까요? 🤔
LLM은 ‘모르겠다’라는 대답을 훈련 중에 배운 적이 없습니다. 훈련 데이터에는 그런 패턴이 거의 없기 때문이지요. 답을 모르면, 혼나기 싫은 LLM은 훈련 때 배운 텍스트를 뒤적이며, 통계에 기반해 가장 그럴듯한 답을 만들어낼 뿐입니다.
여기서 문제는, 언어에는 일정한 규칙이나 패턴이 있는 부분도 있지만 사실상 무작위에 가까운 부분도 많다는 점입니다. 철자법이나 문법에는 일관된 규칙이 있어서 LLM이 데이터를 많이 보면 정확하게 학습하지만, 누군가의 생일이나 특정 문서의 제목 같은 정보는 데이터에 뚜렷한 패턴이 없는 경우가 많습니다. 마치 수백만 장의 강아지와 고양이 사진을 보고 둘을 구분하는 건 가능하지만, 특정 사진 속 강아지의 생일이 언제인지는 학습을 시킨다고 해도 맞힐 방법이 없는 것과 같습니다. 아무리 알고리즘이 좋다고 해도 말이지요. 이처럼 등장 빈도가 매우 낮은 정보에 대해서는 통계적으로 추측할 수밖에 없기에, 틀릴 가능성 또한 올라가게 됩니다. 🚨
연구진은 이러한 오류를 분석하기 위해, 언어 모델이 생성한 문장이 유효한지 판단하는 테스트를 준비했습니다. 'Is-It-Valid(IIV)' 테스트인데요. IIV 테스트는 LLM에게 직접 문장을 만들게 하는 대신, 주어진 문장이 유효한지 아닌지만 판별하게 합니다. IIV 문제를 못 푼다는 건 정답과 오답을 섬세하게 구별하지 못한다는 뜻인데요. 그렇다면 오답을 만들 확률 또한 높겠지요?

언어 모델 출력이 유효한지 여부를 분류하는 'Is-It-Valid' 테스트 결과. 출처: 논문
그림 왼쪽에는 모델에게 테스트로 제공한 유효한 답(valid examples)과 잘못된 답(error examples)을 볼 수 있습니다. 오른쪽에는 (+)와 (-) 부호로 각 문제당 모델이 내린 평가 결과를 보여주는데요. 점선은 분류기를 뜻합니다. 복잡해 보이지만, 사실 단순한 결과입니다! 👇🏼
-
첫 번째는 철자법처럼 뚜렷한 패턴이 있는 경우입니다. 분류기를 기준으로 정확하게 나뉘어 있지요? 철자법에 대해 워낙 많은 데이터를 갖고 있기에 모델은 이를 정확히 구분했습니다.
-
두 번째는 단어 안에서 알파벳을 세는 식의 계수 문제 예시인데요. 성능이 다소 떨어지는 단순 모델은 이를 명확하게 구분하지 못하는 모습입니다.
-
마지막은 사람 생일처럼 데이터에 아무 패턴이 없는 경우입니다. (+)와 (-) 부호가 뒤죽박죽이지요? 이는 성능과 무관하게, 어떤 분류기도 결과가 나쁠 수밖에 없음을 보여줍니다.
연구진은 학습 시킨 데이터에 오류가 전혀 없더라도, 다음에 올 단어를 예측하는 구조인 LLM은 일정 수준의 오류를 출력할 수 밖에 없다고 주장합니다. 하물며 현실의 훈련 데이터에는 자잘한 잘못된 정보나 불완전한 지식도 섞여 있으니, 이런 통계적 오류의 여지는 더욱 커진다는 입장이지요. 언어 모델은 훈련 단계에서부터 모든 것을 완벽히 알 수 없고, 그 빈틈이 환각의 씨앗이 된다고 볼 수 있습니다. 🌱
이제, 어쩌지?
그럼, 우리는 어떻게 해야 할까요?
연구진은 AI가 자기가 모르는 영역에서는 솔직해질 수 있도록 벤치마크 점수 산정 방식을 개선해야 한다고 말합니다. 예를 들어 ‘잘 모르겠습니다’ 같은 답변에 0.5점의 부분 점수를 주고, 틀린 답변에는 -1점의 감점을 주는 식으로 오답에 대한 위험 부담을 늘리는 방식이지요.
현재 널리 쓰이는 주요 벤치마크들이 계속 운 좋은 추측이라도 한 모델에 높은 등수를 주는 한, 개발자들은 소가 뒷 걸음치다 쥐를 잡을 확률을 포기하기 어렵습니다. 평가 방식을 근본적으로 고쳐야만 환각을 줄이는 기술 또한 빛을 볼 수 있습니다. 물론, 어느 정도 답변에 대한 자신이 있을 때 모른다고 답할 것인지, 또 응용 분야마다 오답의 위험도를 어떻게 책정할 것인지 등을 고려해야 하기 때문에 일률적인 감점 규칙을 정하기는 쉽지 않겠지만요.
LLM이 세상 모든 질문에 완벽히 답하기는 불가능합니다. 오픈AI 초기 멤버인 안드레 카파시는 환각은 문제(problem)가 아니라고 말합니다. '꿈꾸는 기계'의 본질적인 특징, 심지어는 언어 모델의 가장 위대한 기능(greatest feature)이라고 표현하기도 했는데요.

무언갈 생성하는 AI에 환각은 피할 수 없는 특징이자, 기능이자, 성질일 수 있습니다. 하지만 이제는 모르면 모른다고 말하는 미덕을 기대해 봅니다. 모르는데 아는 척을 하는 비서만큼 곤란한 게 없을 테니까요.😖
📝 참고자료
- 논문 <Why Language Models Hallucinate>
무슨 일이 있었더라?
