
이것도 눌러야 할까?
🦔 뉴니커 여러분! 회원 가입을 하거나 양식 같은 것을 제출할 때 아래와 같은 모달을 많이 봤을 거예요.
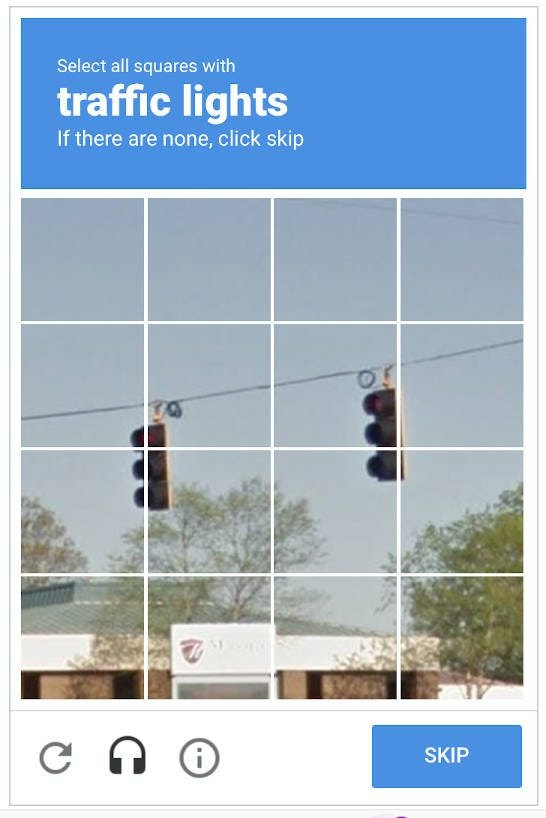
컴퓨터가 "나를 조종하는 것이 사람인지 스팸 봇인지 확인해야겠어!"라고 질문하는 건데요. 바로 캡챠(CAPTCHA)예요.
이런 테스트를 맞닥뜨리면 16개의 타일 중 어떤 타일에 신호등이 포함되어 있는지 눌러야 하는데요, 다들 엄청나게 헷갈렸던 경험이 있을 거예요. (저만 그런 거 아니죠?)
신호등이 뭔지 몰라서 헷갈리는 게 아니죠.

대체 이렇게 아주 약간만 걸친 타일은 눌러야 하나? 말아야 하나? 바로 이 문제입니다. 우리는 이 물음을 해결하기 위해 캡챠의 뜻, 어떻게 변해왔나, 어떤 종류가 있나 등등을 차근차근 알아보도록 해요!
🍎 비운의 수학자, 앨런 튜링

여러분, 영화 <이미테이션 게임> 보셨나요?
베네딕트 컴버배치가 연기한 이 영화의 주인공, 앨런 튜링을 먼저 알아야 해요.
세계 2차 대전 당시 독일군은 전쟁 중 통신 암호화 장치인 "에니그마"로 군사 명령을 암호화했어요.
이걸 풀기는 아주 어려웠어요. 왜냐면 암호가 매일 바뀌어 수조 가지 조합이 가능했기 때문이죠!
그런데 튜링은 해냈어요. (덕분에 세계 2차 대전은 2년 정도 단축됐다고 평가받아요 👍)

이렇게 천재적인 두뇌와 끈기를 가진 튜링은 "튜링 머신"이라는 걸 만들기도 했는데요, 이건 "계산 가능한 모든 알고리즘을 표현할 수 있는 추상적 기계"예요. 말이 조금 어렵지만 한 마디로 하자면 "현존하는 모든 컴퓨터의 논리적 모델"인 것이죠!
튜링은
이에요.
튜링은 1950년에 논문 「Computing Machinery and Intelligence」를 발표하며 이렇게 물었어요.
이때 제시한 실험이 바로 튜링 테스트죠. 쉽게 말해 인간이 대화할 때, 상대방이 사람인지 기계인지 구별할 수 없다면 그 기계는 '지능적'이라고 본 거예요. 아래 그림에서 C는 본인이 컴퓨터인 A와 대화하고 있는지, 사람인 B와 대화하고 있는지 구별해야 해요. 만약 구별하지 못한다면 컴퓨터 A는 충분히 지능적이라고 볼 수 있죠.
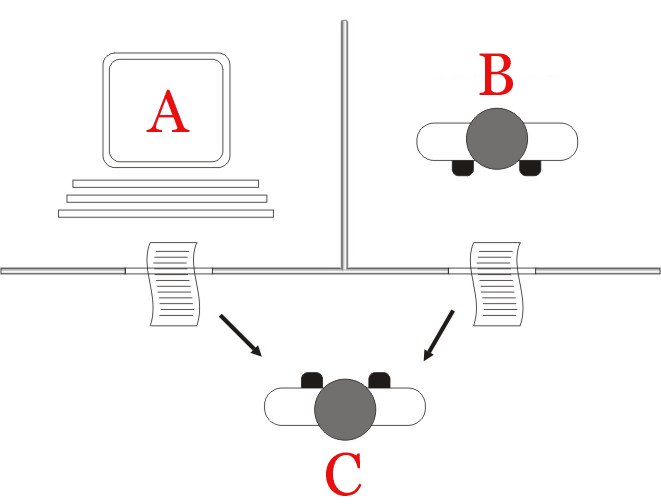
좋아요. 사람이 컴퓨터를 테스트하는 것이 "튜링 테스트"예요.
그 반대는 컴퓨터가 사람을 테스트하는 것일 텐데요,, 이게 사실상 CAPTCHA라고 볼 수 있어요!
왜냐구요? 웹사이트가 현재 접속한 대상이 인간인지 아니면 자동 봇인지를 판별해야 하기 때문이죠.
아차차 다음 챕터로 넘어가기 전에,, 앨런 튜링에 "비운의 수학자"라는 별명이 붙은 이유를 가볍게 알아볼게요.
튜링은 전쟁이 끝나고 동성애자라는 이유로 영국 정부에 의해 기소됐어요. 당시 영국에서 동성애는 불법이었죠.
그래서 강제로 화학적 거세를 당했고 1954년에 사망했어요. (자살로 추정돼요. 튜링의 시신 옆에 청산가리가 묻은 사과가 있었는데 이것이 반쯤 베어 먹은 상태로 발견됐죠. 혹자는 이것이 애플 로고와 상관있는 거 아니냐,,라고 주장하기도 하지만 이는 전혀 상관없다고 해요.)
이후 2013년 영국 정부는 이에 대해 공식 사과했고 2017년에는 튜링 법이 제정되어서 과거 동성애 혐의로 처벌받은 사람들의 전과를 사면하게 되었죠!
🍖 누가 스팸 좀 없애주세요!
CAPTCHA라는 이름 자체는 2003년 카네기멜런 대학의 루이스 폰 안 등이 처음 불렀는데요, CAPTCHA스러운(?) 것의 역사는 1990년대 후반까지 거슬러 올라가요.
초기 인터넷 검색 엔진인 AltaVista는 1997년(제가 태어난 해군요 헤헷) 무분별한 자동 URL 등록으로 몸살을 앓았어요. (참고로 AltaVista는 구글이 등장하기 전, 세계에서 가장 강력했던 웹 검색 엔진이었답니다! 자동으로 웹페이지를 수집하고 검색어와 관련된 페이지를 바로 찾아주는 검색 엔진이었죠.)
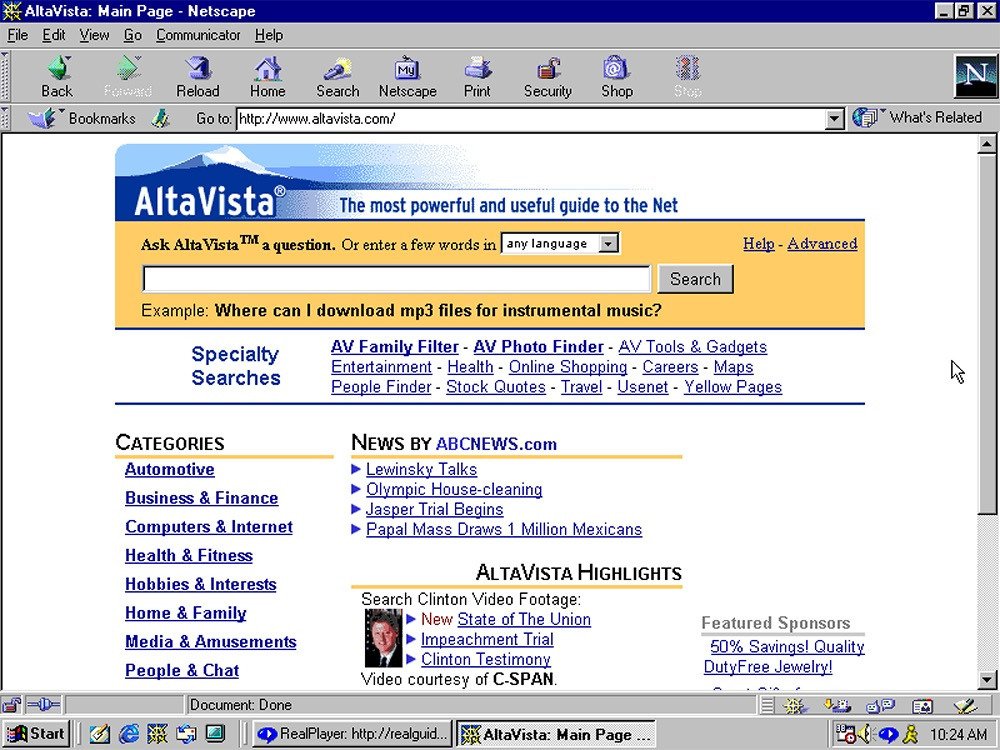
그래서 수석 과학자 안드레이 브로더는 🔎 OCR 기술로 읽기 어려운 무작위 문자열 이미지를 생성해서 사람이 입력하게 하는 방법을 고안했어요.
아래 사진을 보세요! 어떤가요?
지금이야 chatGPT 초기 모델로도 가볍게 풀겠지만 당시에는 기계가 도무지 풀 수 없는 어려운 문제였죠.
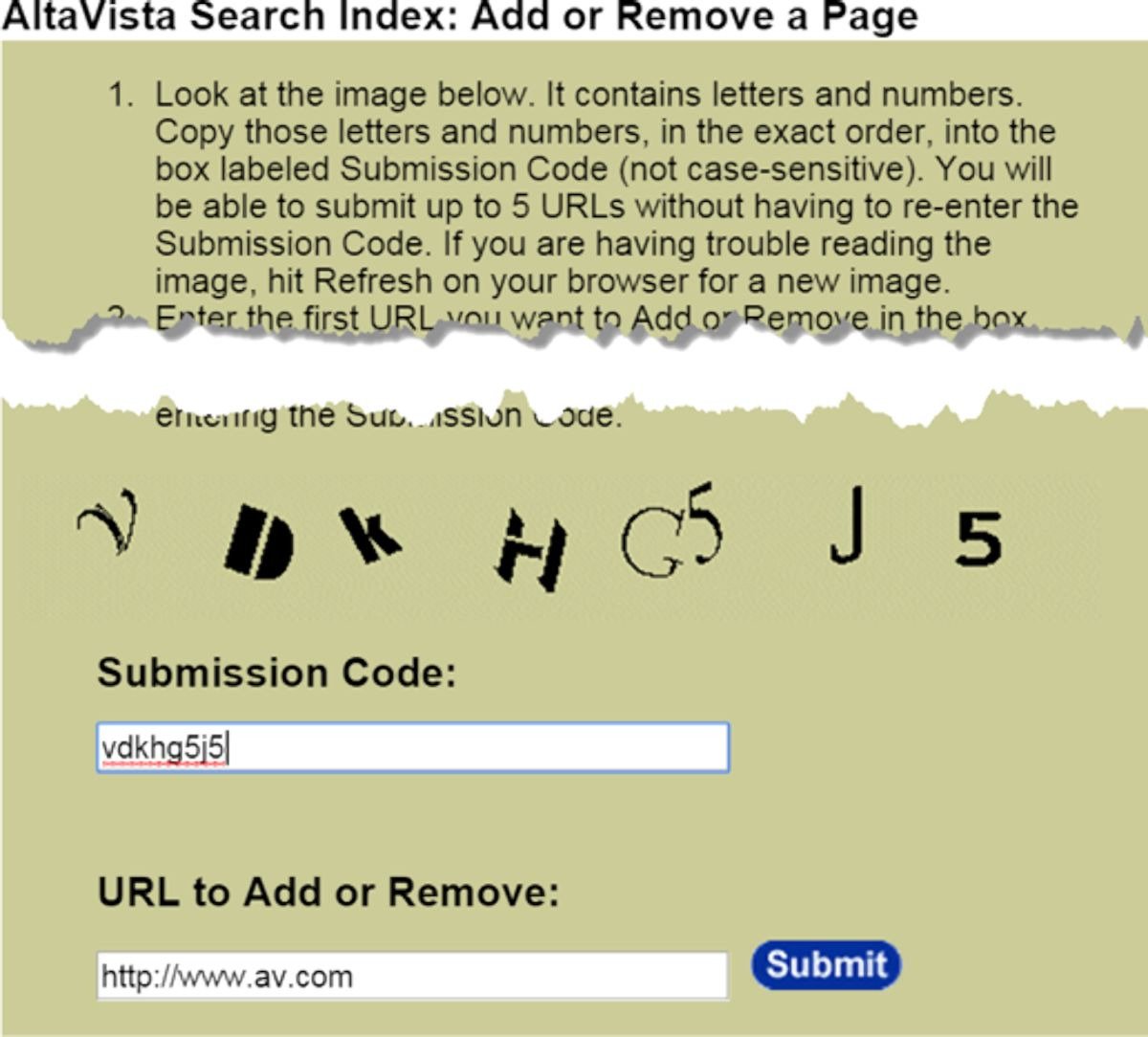
덕분에 도입 1년 만에 스팸 URL 등록이 95%나 감소하게 됐어요!
이후 2000년대 초, 야후도 채팅방의 스팸 봇 문제로 골머리를 앓았어요. 야후는 카네기멜런 대학 연구진에 이 문제를 해결할 수 있는지 의뢰했고, 루이스 폰 안 팀이 GIMPY라는 시스템을 제안했어요. 아래 사진에서 보이듯 이미지 속에 약간 왜곡된 문자열을 넣고 이를 정확히 입력하게 하는 시스템이었죠.
(개인적으로는 이전 버전보다 더 풀기 쉬워진 것 같습니다만,,?)

이후 2003년에 이 연구진이 논문 「CAPTCHA: Using Hard AI Problems for Security」을 발표하며 CAPTCHA라는 용어를 공식적으로 정의하고 상표 등록까지 했어요. 이는 "Completely Automated Public Turing test to tell Computers and Humans Apart"의 줄임말이죠.
"컴퓨터와 인간을 구별하기 위한 완전 자동화 공개 튜링 테스트" 정도로 번역하면 되겠네요.
텍스트 기반의 CAPTCHA는 인터넷의 발달과 함께 전 세계의 웹사이트에 폭발적으로 퍼지기 시작했어요.
⏰ CAPTCHA 푸는 시간이 아까운 것 같아요
그래요. 스팸 방지에는 효과적인 건 알겠어요.
그런데 이런 의미 없는 것에 사람들의 시간과 노력이 들어가는 것은 커다란 낭비가 아닐까요?
(실제로 한 연구에 따르면 CAPTCHA를 풀면서 소모하는 시간의 경제적 가치가 연간 61억 달러(약 8.6조 원)에 달한다고 해요!)
그래서!
루이스 폰 안이 또다시 등장했는데요,
2007년에 reCAPTCHA를 선보였어요.
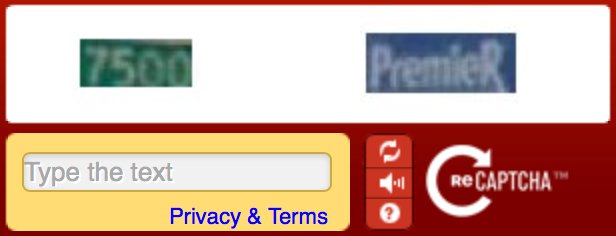
(저는 개인적으로 reCAPTCHA가 그냥 CAPTCHA보다 훨씬 익숙하네요. 여러분은 어떠세요?)
reCAPTCHA에서 사용자는 두 단어를 입력해야 하는데, 하나는 이미 시스템이 답을 아는 단어예요. 이용자가 사람인지 스팸 봇인지를 확인하는 용도죠. 다른 하나는 아직 답을 모르는 단어예요. 여러 사용자들이 같은 답을 내놓으면 그 답을 곧 올바른 답으로 인식하고 이 결과가 책이나 신문의 디지털화 작업에 이용돼요.
그렇습니다! 여기서 보이는 단어 이미지는 책이나 신문처럼 종이로 존재하는 문서를 스캔한 이미지예요. 사람들이 답을 입력하는 노력이 곧 스캔한 이미지를 텍스트화하는 것이죠.
이 덕분에 뉴욕 타임스는 1851년부터 1980년대까지 약 1,300만 기사의 스캔본을 대규모로 디지털화했어요. 2009년에는 구글이 reCAPTCHA를 인수하고 Google Books 프로젝트에 활용해 옛 서적 스캔본이나 구글 스트리트 뷰 사진 속 표지판을 읽는 데도 이 기술을 활용했어요. 전 세계 인구 10억 명 이상이 자신도 모르는 사이에 이미지를 텍스트화하는 데 기여한 셈이죠.
이후 reCAPTCHA는 reCAPTCHA v2로 업그레이드돼요.
reCAPTCHA v2는 먼저 아래와 같은 체크박스를 선보여요.
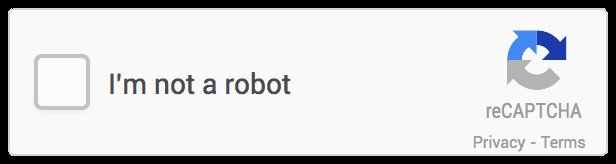
"나는 로봇이 아니에요" 체크박스를 누르는 형태죠. 아마 많이 보셨을 거예요.
근데 그동안 이런 생각이 들지 않으셨나요?
정답은 바로 "사용자의 행동 패턴"이에요.
즉, 버튼을 누르기 위해 마우스가 이동한 궤적은 어떻게 되는지, 클릭하는 타이밍은 어떻게 되는지, 사이트 내에 다른 것과 상호작용한 기록이 어떤지, 기타 쿠키나 브라우저 정보가 어떤지,,,,,,,
등등을 모두 파악해서 사람을 식별하는 첨단 시스템인 것이죠.
사용자 입장에서는 귀찮음이 거의 0로 수렴하게 됐으니 이보다 좋은 게 있을까요!
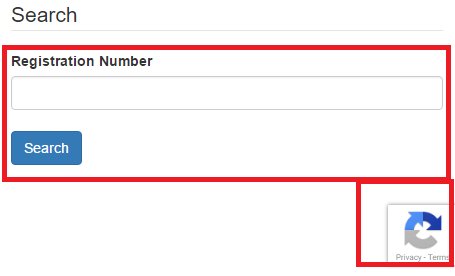
나중에는 Invisible reCAPTCHA v2도 나와요. 아무것도 없이 그냥 우측 하단에 reCAPTCHA 로고만 보이죠?
그렇습니다! 사용자가 할 것은 딱히 없습니다. 브라우저에서 하는 모든 활동이 자동으로 시스템에 입력되고 이것으로 판별하게 됩니다.
확실히 사람 같으면 오케이! 하고 넘기는데 뭔가 애매하다,,? 그럼 두 번째 문제를 냅니다.
두둥! 그게 바로 위에서 본 이 신호등 사진이에요. (사실 요즘은 체크박스 클릭 단계에서 끝나는 경우가 많은 것 같아요. 아마 사용자의 행동 패턴 분석만으로도 사람과 기계를 구분하는 기술이 많이 발전했기 때문이겠죠?)
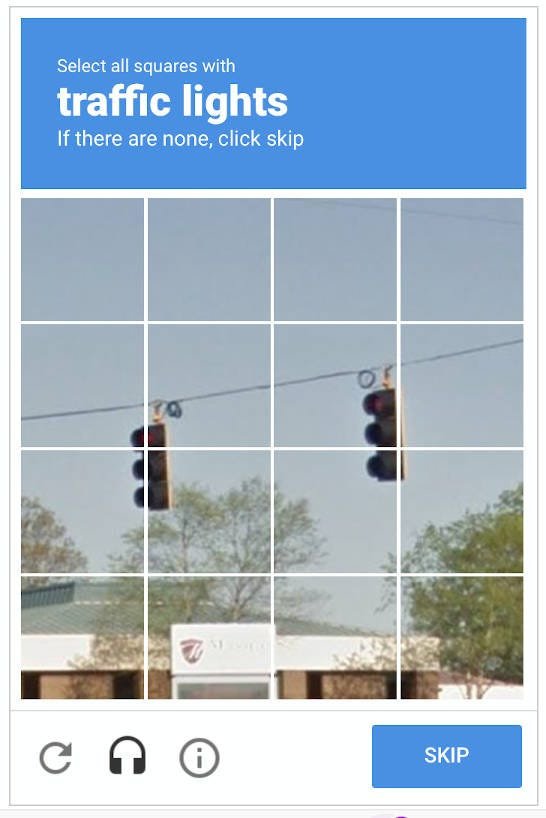
이름하여 reCAPTCHA challenge image입니다! 아직까지 널리 쓰이고 있어요. 여기서 사용자들이 낸 답을 활용해 자율주행 자동차 AI 학습에 사용하고 있으니 구글로서는 얼마나 소중한지요.
그래요. 우리가 처음에 가졌던 의문에 대한 답을 알아봅시다.
저 모서리만 걸친 칸도 눌러야 할까요? 결론부터 말하자면,
🙆 네! 모서리에 살짝이라도 걸쳐 있다면 누르는 편이 낫습니다!
왜죠? 차근차근 알아봅시다.
그림을 해석할 수 있는 비전 AI형 봇은 각각의 칸에 대해서 "이 칸에는 신호등이 포함되어 있을까? 아닐까?"를 판단해요.
그런데! 신호등이 확실히 있다/없다 이런 식으로 딱 잘라 계산되는 게 아니고 93%의 확률로 있다, 2% 확률로 있다 등 확률을 매기죠. 결과적으로 이 타일을 누를지, 말지는 확률이 특정한 값보다 높은 경우에만 누르게 될 거예요.
즉, 특정한 값보다 낮은 확률의 애매한 타일은 클릭을 안 하는 쪽으로 일관되게 치우칠 가능성이 높아요. 반면 사람의 경우, 기계적으로 신호등이 있을 확률, 없을 확률을 계산한다기보다 "요건 있네(클릭), 요건 없네(안 클릭), 요건 애매하네(클릭)" 이런 식으로 애매함 자체를 간파할 수 있어요.
궁금증이 많은 여러분은 아마 이런 생각을 가질 수 있을 것 같아요.
아마,,, 먼 훗날에는 가능할 수도,,,,,? 있겠지만 아직까지는 완벽하게 해결하지는 못한다는 게 정론이에요.
왜냐구요?
그림을 해석하는 정교한 AI는 애초에 "이미지를 정확히 해석해서 신호등이 있는 타일을 정확하게 눌러라"라는 목표를 중심으로 학습하기 때문이죠. 맞습니다! "정확한 객체 인식"이 목표예요.
그런데 여기에 사람처럼 애매한 것도 누르게끔 학습을 한다면,,? 이것의 목표는 곧 "정확한 객체 인식"의 능력을 낮추는 것이죠. 서로 정면으로 충돌하는 두 가지 목표를 모두 이루도록 하는 것이기 때문에 모델이 상당히 불안정해져요. 이도 저도 아닌 게 된답니다. (모델 직접 학습해 보신 분들은 알겠지만 Loss를 올리는 것과 낮추는 것 두 가지를 동시에 목표로 삼는다? 이건 모델이 바보 되는 지름길이죵)

🎨 엄~~~청나게 다양한 CAPTCHA의 세계
CAPTCHA는 종류가 엄~~~청나게 많아요. 몇 가지만 예시로 살펴보자면,
첫 번째는 슬라이드형이에요.
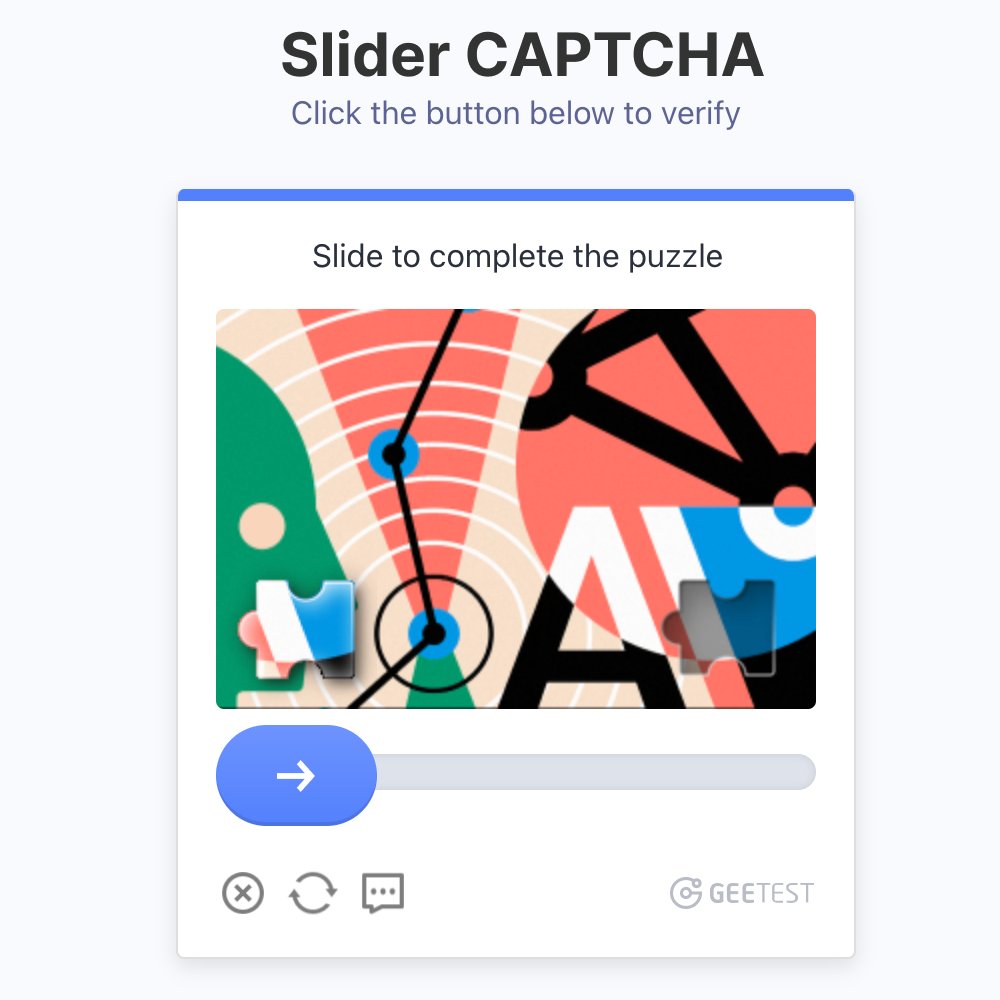
직관적이니 설명은 생략하죠.
두 번째는 순서 클릭형이에요.

세 번째는 회전형이에요.
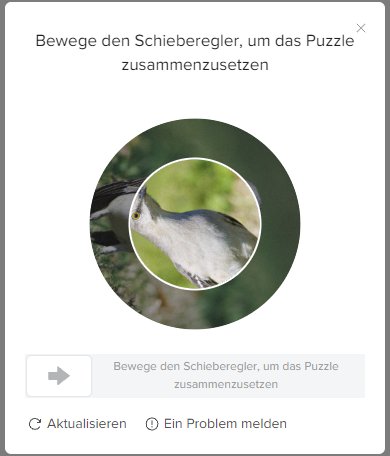
네 번째는 3D·동적 퍼즐형이에요.
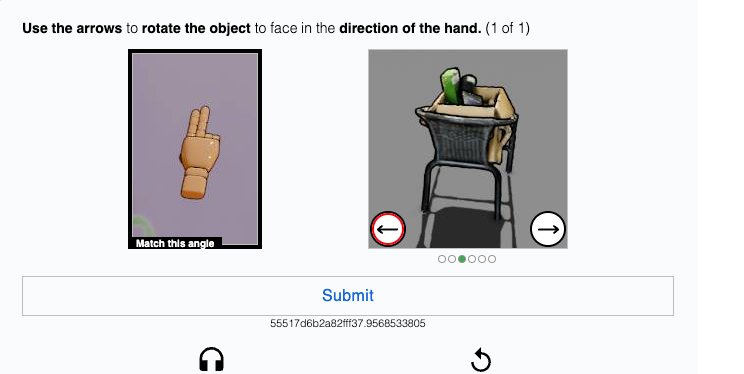
다섯 번째는 Diff-CAPTCHA예요.

이건 문자를 변형하다 못해 아예 그림에 녹여낸 캡챠예요.
여섯 번째는 올해(2025년) 나온 따끈따끈한 IllusionCAPTCHA예요.

두 가지 사진을 제시하고 오른쪽 사진에 왼쪽 사진과 비슷한 "착시 요소가 있는지"를 묻는 식이에요. 아직까지는(?) 최첨단 AI 비전 모델들도 정확히 인식하지는 못했다고 해요. (물론 언젠가는 뚫리겠죠?)
사실 훨씬 더 많아요! 만들기 나름이죠.
하지만 결국 핵심은 두 가지 축으로 귀결돼요.
🗡️ 그럼 당신의 창으로 당신의 방패를 찌르면 어떻게 됩니까?
그래도 그래도 그래도
여러분은 이런 생각을 하실 거예요.
"(아무튼) 그런 사람사람스러운(?) 것도 결국 AI가 해결할 수 있지 않나?"
네 맞습니다.
CAPTCHA와 봇 사이의 경쟁은 진화할수록 빨리 달리는 먹이와 포식자의 관계처럼 끊임없는 진화의 역사라고 할 수 있어요. 군비 경쟁인 것이죠.
(예전에 하던 크아가 생각나네요. 강퇴하기를 막기 위한 강퇴반사 실드가 있고 그걸 막기 위한 슈퍼방장이 있던 시절,,,)
예를 들면, 구글이 2017년 3월에 Invisible reCAPTCHA를 출시하자마자 며칠 지나지 않아서 우회 서비스인 2Captcha가 "우회 가능" 공지를 냈어요.
심지어는 AI를 사용하지 않아도 이를 해결할 수 있어요. 바로 다른 사람에게 대신 풀어달라고 시키는 것이죠! 인건비가 아주 저렴한 개발도상국에 부탁하면 1,000개를 푸는 데 1달러 정도만 지급하면 된다고 합니다. 이런 방법은 애초에 사람이 푸는 것이기 때문에 막을 수 있는 방법이 논리적으로 불가능하겠죠? (막힌다면 그건 사람을 막는 건데 말이죠?)

모든 AI 관련 담화들이 그렇듯이 이 질문으로 귀결될 것 같아요. "AI가 사람을 완전히 모방한다면 인간만의 지능(혹은 특성, 성격, 감성)을 증명할 수 있는 시험이 무엇이 될까요?"
여러분의 상상력에 바톤을 넘기며 글을 마칠게요.
그럼 그때까지 모두 안녕! 👋